The 2026 Guide to Document Data Extraction using AI
A practical guide to AI-powered document data extraction for process owners and automation teams. Learn best practices for extracting structured data from PDFs and unstructured documents.

In this article, we’ll look at how AI is used for data extraction. In this context, data extraction means pulling structured information from PDFs and images, typically as part of document processing and workflow automation initiatives.
With more than 10 years of experience as a machine learning engineer building document processing systems, I’ve seen the field evolve from template-based legacy tools to large language models (LLMs). In this post, I’ll summarize what consistently works, and what tends to fail, when applying AI to data extraction, based on deployments across both startups and Fortune 500 companies.
TL;DR
If you’re just looking for a quick step-by-step guide on how to use AI to read documents, I recommend checking out some of the following articles:
Who is this guide for?
This article is written for process owners, automation managers, and digital transformation teams who want to automate business processes that rely on unstructured documents and are looking for practical best practices to do it right.
The case for AI in data extraction
It may sound absurd today, but not long ago many organizations needed convincing that AI could reliably process documents. Even now, some organizations remain skeptical. The benefits, however, are clear:
Higher accuracy, fewer errors. Manual mistakes are costly, especially when they're allowed to propagate downstream into ERP and reporting systems.
Easier to maintain (when built correctly). Modern AI workflows can be updated and improved without rebuilding the entire system.
Significant time savings. Compared to legacy tools and manual handling, enterprises often reduce processing time by 80% or more.
For organizations on the other end of the spectrum, where leadership has mandated broad AI adoption, document data extraction is often a good place to start and score a quick win. The value is tangible, and the risk is relatively low when implemented properly.
Examples of good use cases
Here are examples of areas where AI-powered data extraction consistently delivers value:
Finance teams: Extract and process data from invoices, bank statements, P&Ls, financial reports, and contract notes.
Procurement and logistics: Extract and process data from packing slips, order confirmations, bills of lading, and other operational documents.
You rarely have to look far to find strong use cases in these functions. The main constraint is typically system integrations, not a lack of automation opportunities.
Design your business process for AI
A successful AI automation project starts with a process that is intentionally designed (or redesigned) with AI in mind. In most cases, introducing an AI model changes the workflow itself.
When redesigning a data extraction process for AI, consider:
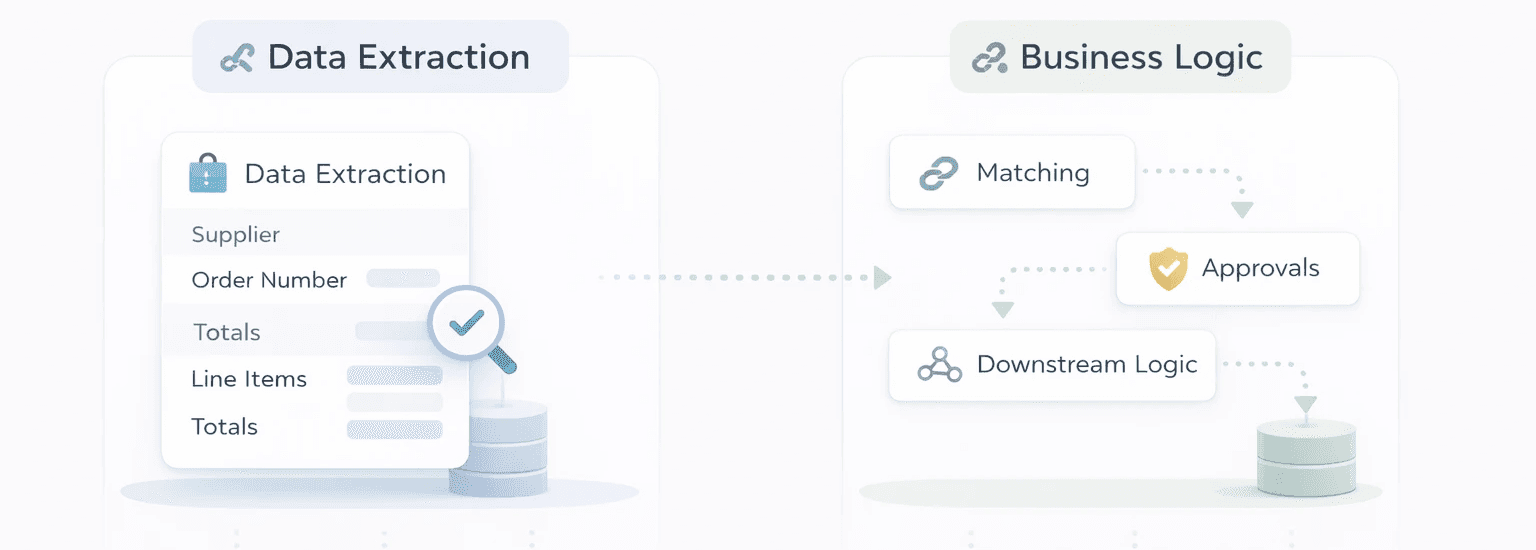
1) Making a clear distinction between data extraction and business logic.
For example, extract structured fields from a purchase order (e.g. supplier, order number, line items, totals) as one dedicated step. Then handle matching, approvals and downstream logic in separate steps.
This separation makes complex processes easier to manage because you’re breaking them into smaller, well-defined sub-processes. It also makes it much simpler to increase automation over time. You can improve extraction accuracy independently from your business rules—or refine your approval logic without changing the extraction layer. That modular approach is what allows automation to scale in a controlled way.
2) Simplifying the process, if possible.
Eliminate unnecessary edge cases wherever possible. AI performs best in well-defined, standardized environments. The more variation and exceptions you allow, the harder it becomes to achieve high automation rates. Simplifying the process is often the quickest way to increase the automation degree in your processes.
What often fails is trying to “add AI on top of the existing process” without rethinking how the process should work in the first place. That usually happens because people are afraid to disrupt what’s already running.
Redesigning a process is easier said than done. It often means challenging business units on why things are done a certain way and whether those choices still make sense. In some cases, it may even mean walking away if the organization isn’t ready to standardize or simplify.
You can lead the horse to water, but you can’t make it drink. Automation only works when there’s real willingness to adapt the process, not just bolt AI onto the old one.
Choose the right tech stack
After mapping the process, the next step is deciding how to implement it, and the first step is choosing the right tech stack.
I strongly believe adoption of workflow automation platforms like Zapier, Power Automate, and n8n is still in its early stages. The core value proposition is compelling: instead of relying on large, monolithic systems, companies can combine specialized best-of-breed tools through APIs. These automation platforms act as the glue by coordinating data flows and orchestrating processes across systems without requiring deep technical expertise or creating significant technical debt.
I recommend a setup like this:
An automation platform (e.g., Zapier, Power Automate, or n8n) to orchestrate workflows, business logic and integrations.
A document data extraction tool for unstructured documents. A purpose-built solution such as Cradl AI is designed for high-accuracy extraction and human-in-the-loop validation.
This combination gives you flexibility and control: workflows tailored to your business processes, without unnecessary technical debt or long-term maintenance overhead.
Keep humans in the loop
As Mike Tyson once said:
Everybody has a plan until they get punched in the face.
The same applies to automation. No matter how detailed and well thought out your flowcharts are, things tend to get messy once you move into production. For most real-world use cases, fully removing humans from business processes is still unrealistic.
When designing a data extraction workflow, plan for a human-in-the-loop from the start. This is essential for managing risk, handling edge cases, and resolving low-confidence predictions. Done properly, it also creates a feedback loop that improves accuracy over time.
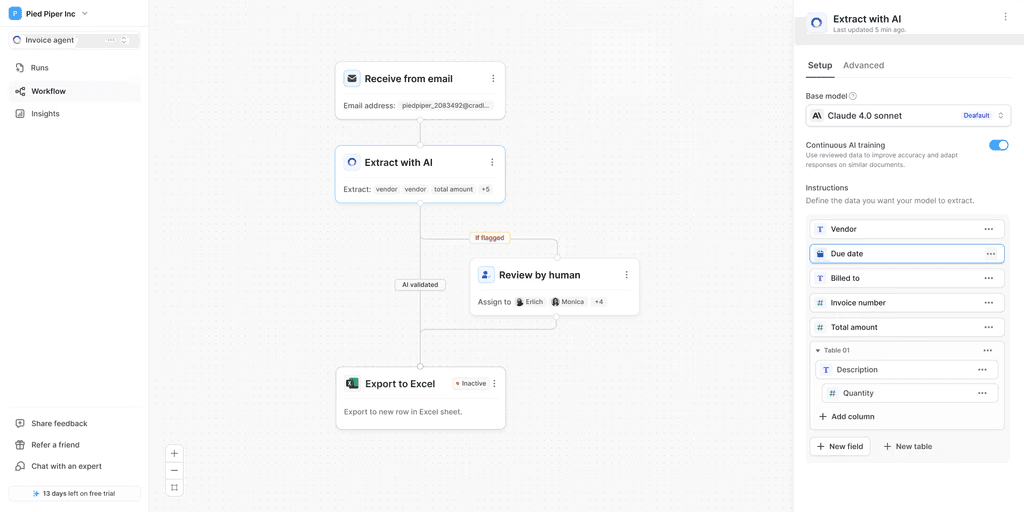
For most AI-driven document processes, a robust and well-designed human verification layer isn’t optional, it’s a core requirement for long-term success.
Validate only what you need
A big part of making AI extraction actually work in production is targeted validation. Instead of having someone double-check every single field, you only review the ones that are likely to be wrong.
This is made possible by using confidence scores. AI models can often return a confidence score for predictions they make. In simple terms, it’s the model’s estimate of how likely it is that the value is correct. And while that might sound like a technical detail, it’s what makes targeted validation possible.
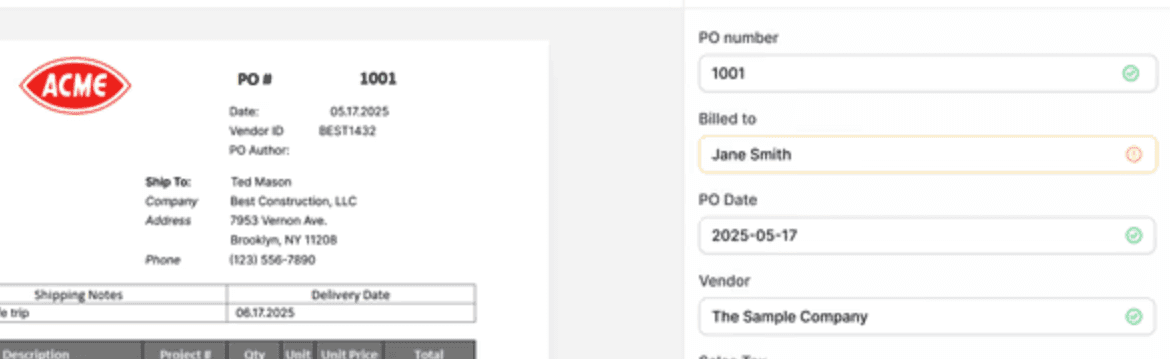
If one field comes back with 99% confidence and another with 80%, they shouldn’t be handled the same way. The 80% field is the one that deserves extra attention. In many cases, it makes sense to skip reviewing the 99% field entirely and only validate the lower-confidence ones. That can save a significant amount of time and, in many situations, actually improve overall accuracy.
The reason is simple: while reviewing everything sounds safe, in practice it leads to fatigue. When errors are rare, people go on autopilot. Important issues are more likely to slip through because every field gets the same level of attention. Targeted validation keeps reviewers focused on what truly needs scrutiny—improving both accuracy and efficiency at the same time.
Risks, and how to deal with them
A common concern when implementing AI workflows is risk. How do you deal with a seemingly non-deterministic AI model that might not always produce identical outputs for the same document? Here are the key risks in AI-powered document processes that I've found to be most real:
Hallucinations. The model may infer or “fill in” values that aren’t actually present in the document. This is more common than many expect and needs to be explicitly guarded against.
Poorly configured automation thresholds. If confidence thresholds are set too low, you introduce unnecessary risk. If they’re set too high, you lose efficiency and end up reviewing almost everything anyway. Finding the right balance is critical.
Over-reliance by human validators. When the AI is usually right, reviewers can become less attentive. That’s why targeted validation is so important, it directs attention to where uncertainty is highest and human involvement is actually needed the most.
All of these risks can be mitigated with a modern, purpose-built document automation tool like Cradl AI. That said, it usually takes some iteration to find the right balance between automation rate, accuracy, and acceptable risk.
Wrapping up
Hopefully, this guide gave you a practical sense of how AI can be used for document data extraction. If you’re looking for a straightforward way to automate document processing and data entry in back-office workflows, tools like Cradl AI can save you a significant amount of time.
Regardless of which software you choose, the key is to apply the right principles. Hopefully, these lessons help you avoid common pitfalls as you start or scale your data extraction efforts.